Explore advanced Regex techniques for handling quoted strings with escapable quotes, with practical insights for Behat users and developers.

Metal Toad is an AWS Managed Services provider. In addition to Regex tips we recommend checking out our article on how to host a website on AWS in 5 minutes.
This post is a long-format reply to Jonathan Jordan's recent post. Jonathan's post was about the non-capturing backreference in Regular Expressions. He and I are both working a lot in Behat, which relies heavily on regular expressions to map human-like sentences to PHP code. One of the common patterns in that space is the quoted-string, which is a fantastic context in which to discuss the backreference (and also introduce lookarounds). Please read hist post first, as from here on the tone and perspective of this post is reply-oriented.
In Behat, this (non-capturing groups) is helpful to not pollute your step-definition arguments with certain groups that improve the usability of your step but don't change how it behaves. For example, you can offer steps a choice between "click" and "press" with (?:click|press) without adding an argument to your method.
But it's worth noting that what you're discussing here (?:) is essentially the non-back-reference. It's a way to group things and tell the engine that you don't need to refer back to what was consumed by the group. Behat doesn't often use the real notion of backreferences: re-using the captured group as part of the matching requirements. The basic regex feature is that once you have a capturing group, you can use the espression \1 to refer to that group. You showed an example snippet used often in Behat's Mink extension:
(?P<option>(?:[^"]|\\")*)
This is essentially an attempt to match any string of characters up to a closing quote, considering that we should allow people to escape their quotes like this: "some \"value\" is safe". However, I think this pattern, while clean, is lackluster in that it doesn't support single quotes. What a great opportunity to explore how useful backreferences can be! Basically, we can use a capturing group's backreference to tell the Regex engine that a string should end with the same quote character that started it. So, what follows is an example of how Behat could improve it's usual quoted-string pattern with this backreference feature, along with some negative lookbehind/lookahead assertions (which I understand might be more than this conversation wanted, but it's a cool thing to explore and this is a great context). This will feel a bit complicated at first, but we'll break it down. Here is my proposed replacement pattern:
((?<![\\])['"])((?:.(?!(?<![\\])\1))*.?)\1
This translates to english like this:
1. Match a single or double quote, as long as it's not preceded by \
2. Store that match in a way that I can reference later. (with \1)
3. Continue matching ANY characters...
3.1 As long as they aren't followed by the same quote that was matched in #1...
3.2 unless that quote was itself preceded by a \, then go ahead and proceed.
4. Once you stop matching (because the next character is followed by the ending quote, match that last character.
So, chunk by chunk:
((?<![\\])['"])
This is our opening chunk, which essentially matches any single or double quote, unless that quote is preceded by a backslash. That's a "Negative Lookbehind", and the (?<!) part does not consume any characters. If we didn't care to be careful about erroneously matching escaped quotes, it could simply be this:
(['"])
Next we want to match any string until we encounter an un-escaped quote, but it must be the SAME (e.g. single vs. double) that was matched at the begining. This is where backreferences come in (we need to reference what was matched at the start in order to tell the engine what to look for). We also need a way to say "anything except", but it's not a character class, so we need negative lookahead for this. The basic algorithm is to keep matching characters as long as they are not followed by the same quote that was used to start the string. Here is the simplified version (e.g. without concern for erroneously stopping for an escaped quote)
(?:.(?!\1))*.?
We can break this down even further. I'll strip out some of the parens for readability; they are essentially to manage what gets captured in the end. The following will match ANY single character that is not followed by the string matched in the first backreference.
.(?!\1)
Think of this as similar to the following:
.(?!["']))
The next important thing to realize is that the last character before the ending quote will not get matched. That's why we add the last .?, to grab that last character. Finally, the whole "interesting" part is wrapped up the the necessary parentheses to capture it.
I've posted an example to Rubular for you to play with!
http://www.rubular.com/r/mP6IRzteSm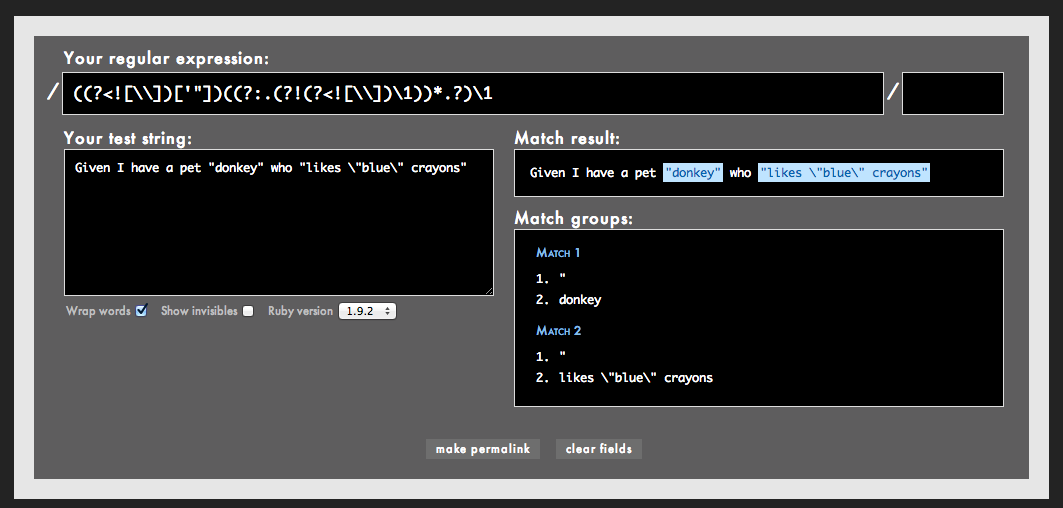
In case it helps cut through the complexity, here's a comparison of "escaping quotes is not supported" and the "escaping quotes works" version. The first one, when matching "this \"string" will only match 'this\'. The second one will match 'this \"string'
(['"])((?:.(?\1))*.?)\1 ((?<![\\])['"])((?:.(?!(?<![\\])\1))*.?)\1
It's probably worth noting that one reason this may be avoided by the community is that the captured results include a group just for the opening quote. The way Behat works, this would garbage-up your method parameters (and you can't not capture that opening quote if you want to use /1). To me, this is a very reasonable thing to be concerned about, and it doesn't exactly appear to be easy to work around, without adding some assumptions and/or complexity that is unneeded.