Artificial Intelligence
What is Amazon Bedrock?
Discover how Amazon Bedrock simplifies AI development with serverless access to top foundation models, customizable options, and cost-efficient...
Understand Amazon Bedrock's flexible AI pricing, optimize costs, and explore provisioning options for deploying generative AI with foundation models on AWS.

Amazon Bedrock—or AWS Bedrock—offers a powerful, fully managed platform for deploying generative AI using foundation models. While its capabilities are expansive, understanding its pricing structure is key to managing budgets and optimizing deployments. If you are new to GenAI or Bedrock we recommend starting with our What is Amazon Bedrock? article.
When it comes to pricing there are two major categories of models: text & multimodal models (ChatGPT style models) and creative models which create images and videos.
Since Amazon Bedrock currently supports 60+ different models in Bedrock, we are going to focus on our top four picks in the text & multimodal models:
And for creative models Amazon Nova—specifically Canvas & Reels—and Stability AI.
You can run Amazon Bedrock in different modes, each of which offers a different pricing scheme:
In On-Demand mode, you’re only billed for the tokens you use in Amazon Bedrock—no time-based commitments. A token is a small unit of text—typically a few characters—that models use to interpret prompts and user input.
Amazon Bedrock Batch mode lets you submit a file with multiple prompts and receive a single output file with the corresponding responses—ideal for large-scale, simultaneous predictions. The results are stored in your Amazon S3 bucket for easy access later. Amazon Bedrock supports batch inference with select foundation models from providers like Anthropic, Meta,and Amazon, offering up to 50% lower costs compared to On-Demand pricing. Some models (like DeepSeek) aren't offered in Batch Mode on Bedrock.
The following table breaks down the costs* for the latest models from our top four provides (outlined above):
| Anthropic models | Price per 1M input tokens | Price per 1M output tokens | Price per 1M input tokens (batch) | Price per 1M output tokens (batch) | Price per 1M input tokens (cache read) | Price per 1M input tokens (cache write) |
|---|---|---|---|---|---|---|
| Claude 3.7 Sonnet | $3.00 | $15.00 | N/A | N/A | $0.30 | $3.75 |
| Claude 3.5 Sonnet | $3.00 | $15.00 | $1.50 | $7.50 | $0.30 | $3.75 |
| Claude 3.5 Haiku | $0.80 | $4.00 | $0.50 | $2.50 | $1.00 | $0.08 |
| Amazon Nova models | Price per 1M input tokens | Price per 1M output tokens | Price per 1M input tokens (batch) | Price per 1M output tokens (batch) | Price per 1M input tokens (cache read) | |
| Amazon Nova Micro | $0.04 | $0.14 | $0.02 | $0.07 | $0.01 | - |
| Amazon Nova Lite | $0.06 | $0.24 | $0.03 | $0.12 | $0.02 | - |
| Amazon Nova Pro | $0.80 | $3.20 | $0.40 | $1.60 | $0.20 | - |
| Amazon Nova Pro (w/ latency optimized inference) | $1.00 | $4.00 | N/A | N/A | N/A | - |
| Amazon Nova Premier | $2.50 | $12.50 | $1.25 | $6.25 | N/A | - |
| Meta models | Price per 1M input tokens | Price per 1M output tokens | Price per 1M input tokens (batch) | Price per 1M output tokens (batch) | NA | NA |
| Llama 4 Maverick 17B | $0.24 | $0.97 | $0.12 | $0.49 | - | - |
| Llama 4 Scout 17B | $0.17 | $0.66 | $0.09 | $0.33 | - | - |
| Llama 3.3 Instruct (70B) | $0.72 | $0.72 | $0.36 | $0.36 | - | - |
| DeepSeek Models | Price per 1M input tokens | Price per 1M output tokens | NA | NA | NA | NA |
| DeepSeek-R1 | $1.35 | $5.40 | - | - | - | - |
* Pricing is for AWS US regions. Pricing for other regions can be found here: https://aws.amazon.com/bedrock/pricing/
For more Amazon Bedrock pricing information, as well as token count limits checkout our publicly available Google Sheet, which tracks the following information:
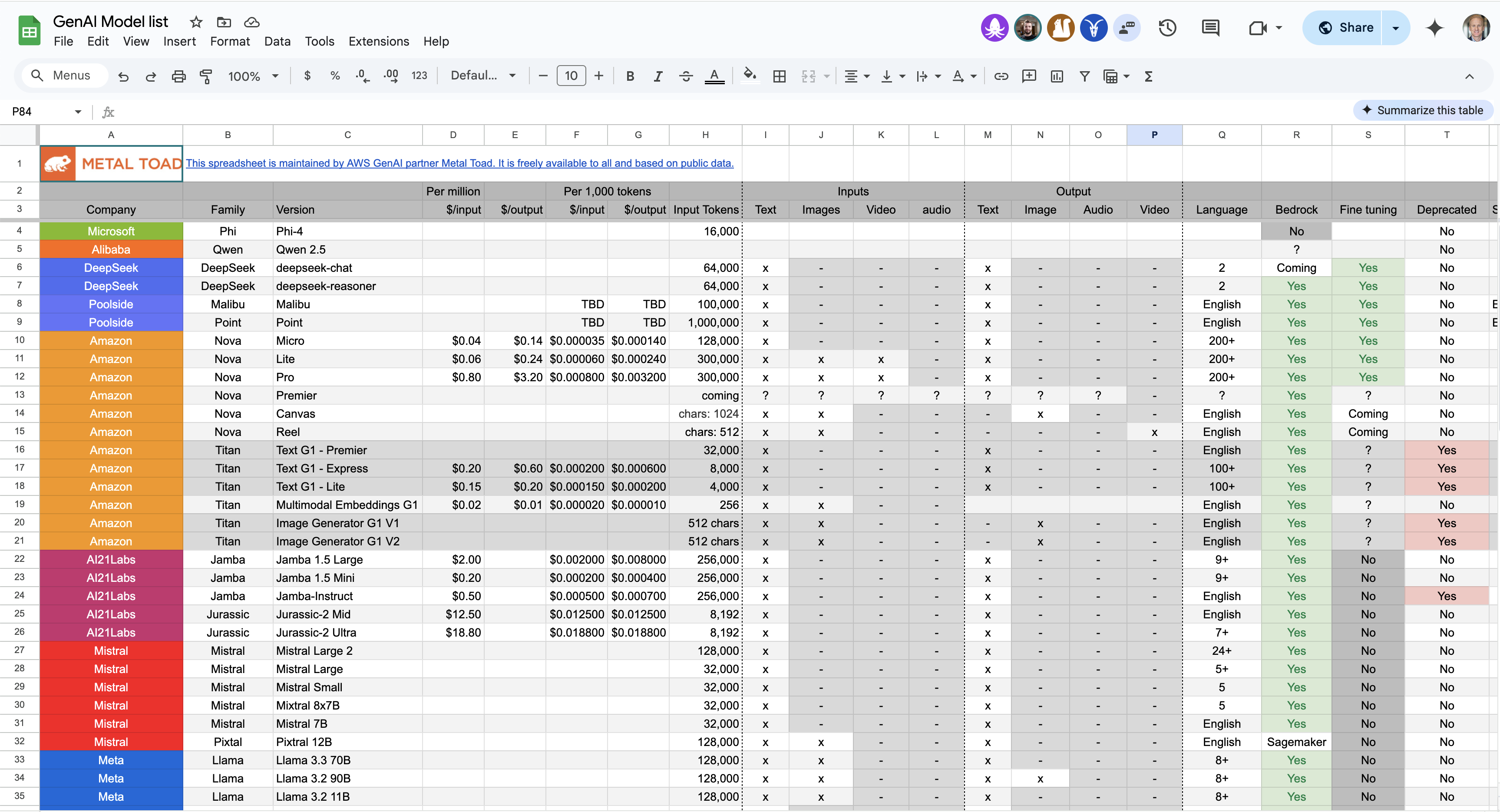
Provisioned Throughput mode allows you to reserve model units for a specific base or custom model, making it ideal for large, consistent inference workloads that require guaranteed performance. This is the only mode that supports access to custom models. Each model unit delivers a set level of throughput, measured by the maximum number of input or output tokens processed per minute. Pricing is hourly, with the option to commit to either a 1-month or 6-month term.
More information on purchasing Provisioned throughput can be found here: https://docs.aws.amazon.com/bedrock/latest/userguide/prov-thru-purchase.html
Latency-optimized inference in Amazon Bedrock delivers faster response times, enhancing the performance of your generative AI applications. This option is available for Amazon Nova Pro, Anthropic’s Claude 3.5 Haiku, and Meta’s Llama 3.1 405B and 70B models. According to Anthropic, Claude 3.5 Haiku runs faster on AWS than anywhere else. Similarly, Llama 3.1 models achieve the fastest performance on AWS compared to other major cloud providers.
You can learn more here: https://docs.aws.amazon.com/bedrock/latest/userguide/latency-optimized-inference.html
Custom Model Import in Amazon Bedrock lets you bring in your previously customized models and run them just like Bedrock’s hosted foundation models—fully managed and available on demand. You can upload custom weights for supported model architectures and serve them using On-Demand mode, with no charge for the import itself. Once imported, the model is ready for use without any additional setup.
You’re only billed for inference, based on the number of model copies needed to handle your traffic and how long each copy remains active, charged in 5-minute increments. A model copy is an instance of your imported model available to handle inference requests. Pricing per minute varies by model architecture, context length, AWS Region, compute unit version, and model copy size tier.
Detailed documentation on this approach can be found here: https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-import-model.html
The Amazon Bedrock Marketplace lets you discover, test, and use over 100 foundation models—including popular, emerging, and specialized options—directly within Bedrock. Models are deployed to dedicated endpoints, where you can choose instance types, set the number of instances, and configure auto-scaling to fit your workload needs.
For proprietary models, pricing includes a software fee set by the model provider (billed per hour, per second, or per request) and an infrastructure fee based on your selected instance type. Pricing is clearly displayed before you subscribe and in the model’s AWS Marketplace listing. For publicly available models, you pay only the infrastructure fee tied to your instance selection.
A complete list of Marketplace Models can be found here: https://docs.aws.amazon.com/bedrock/latest/userguide/bedrock-marketplace-model-reference.html
Beyond running vanilla versions of models, some models allow for fine tuning and other model distillations.
Customizing models incurs separate costs. Fine-tuning charges are based on data volume. For example, Amazon Nova Pro runs at $0.008 per 1,000 tokens. Fine-tuned models must use provisioned throughput for inference.
Amazon Bedrock also allows customers to bring their own pre-trained models through the Bring Your Own Model (BYOM) feature. These are billed by Custom Model Units (CMUs), at $0.0785 per minute per unit. A model using 2 CMUs for five minutes would cost roughly $0.79.
A number of models also have additional tools that can be turned on and they have associated charges. This includes:
Amazon Bedrock Flows is a no-code, visual workflow builder that enables you to design, test, and deploy generative AI applications by connecting foundation models, prompts, agents, and other AWS services into end-to-end solutions.
In Bedrock Flows, you're billed based $0.035 per 1,000 node transitions—each time a node in your workflow executes, it counts as one transition. Charges are calculated from the total transitions across all your flows. Additional costs may apply if your workflow utilizes other AWS services or involves data transfers. For example, invoking an Amazon Bedrock Guardrail policy within your flow incurs charges based on the number of text units the policy processes.
Learn more about Amazon Bedrock Flows: https://aws.amazon.com/bedrock/flows/
To enhance foundation models (FMs) with current and proprietary information, organizations use Retrieval Augmented Generation (RAG)—a method that pulls relevant data from internal sources to improve the accuracy of responses. Amazon Bedrock Knowledge Bases offers a fully managed solution for implementing the entire RAG workflow, including ingestion, retrieval, prompt enrichment, session context management, and source attribution—without the need for custom data integrations. It also enables users to query or summarize a single document without setting up a vector database. For structured data sources, it includes a built-in natural language to SQL capability, allowing you to generate query commands without relocating the data.
Learn more about how to implement Knowledge Based in Amazon Bedrock here: https://www.metaltoad.com/blog/aws-bedrock-knowledge-bases
Amazon Bedrock Guardrails is a feature that helps ensure safe, responsible, and aligned use of foundation models by enforcing customizable policies on model outputs. Each guardrail policy is optional and can be enabled based on your application's specific needs. Policies include content filters, denied topics, sensitive information filters, and contextual grounding checks.
You are charged based on the types of policies enabled. For example, if you enable content filters and denied topics, you will incur charges for both; however, enabling sensitive information filters does not generate any additional charges.
Guardrail usage is measured in text units, with one unit consisting of up to 1,000 characters. Inputs longer than 1,000 characters are split into multiple text units. For instance, a 5,600-character input would be billed as six text units.
Contextual grounding checks compare a reference source and a user query against the model’s response to verify that the output is both relevant and grounded. In this case, the total characters from the source, query, and model response are combined to calculate the number of text units billed.
|
Guardrails policy* |
Price |
|
Content filters (text content) |
$0.15 per 1,000 text units |
|
Content filters (image content) |
$0.00075 per image processed |
|
Denied topics |
$0.15 per 1,000 text units |
|
Sensitive information filters |
$0.10 per 1,000 text units |
|
Sensitive information filters (regular expression) |
Free |
|
Word filters |
Free |
|
Contextual grounding check |
$0.10 per 1,000 text units |
Amazon Bedrock model evaluation helps you compare and assess the performance of different foundation models for your specific use case. You can evaluate models using automatically generated algorithmic scores or human-based evaluations.
Model evaluation is billed based on the inference costs of the models you choose to test. Algorithmic scores—such as relevance, coherence, and fluency—are provided automatically and at no additional cost. If you choose to conduct human-based evaluations using your own review workflow, you'll be charged for the model inference plus $0.21 per completed human evaluation task.
Amazon Bedrock Data Automation is an integrated parsing solution within Amazon Bedrock Knowledge Bases that enhances the relevance and accuracy of responses from multimodal data sources. When configuring a Knowledge Base, you can choose Bedrock Data Automation as your parsing method to automatically extract insights from documents, images, and other rich media—including figures, charts, and diagrams.
As documents and images are ingested, Bedrock Data Automation analyzes the content and extracts structured information, which is then used in downstream steps such as chunking, embedding, and storage. This standardized output helps improve retrieval-augmented generation (RAG) workflows within Knowledge Bases.
Pricing is based on the number of units processed (pages, images, or audio). If the blueprint used to define the fields for extraction contains between 1 and 30 fields, a custom per-unit rate applies. If your blueprint includes more than 30 fields, an additional charge of $0.0005 is applied for each extra field per unit processed.
Intelligent Prompt Routing in Amazon Bedrock enables cost and performance optimization by dynamically selecting the most appropriate foundation model from the same model family based on prompt complexity. For instance, within Anthropic’s Claude family, Bedrock can route simple requests to Claude 3 Haiku and more complex ones to Claude 3.5 Sonnet. Similarly, it can switch between Meta Llama 3.3 70B and 3.18B, or Nova Pro and Nova Lite, depending on the use case.
The routing engine evaluates each prompt to predict which model will deliver the best balance of quality and efficiency. This is especially valuable for scenarios like customer service assistants, where basic queries can be served by smaller, faster, and lower-cost models, while more advanced queries are directed to more powerful ones. Intelligent Prompt Routing can cut costs by up to 30% without sacrificing response accuracy.
Amazon Bedrock Prompt Optimization enhances the effectiveness of your generative AI applications by automatically refining input prompts to improve accuracy and relevance. It rewrites or adjusts prompts before they are sent to the foundation model, helping to optimize both performance and cost.
You are charged based on the total number of tokens in both the original input and the optimized prompt. The pricing is $0.030 per 1,000 tokens processed.
To manage costs effectively, consider batching requests to reduce per-unit charges, caching prompts to reuse inputs, and selecting the most efficient model for your use case. If your usage is predictable, reserving provisioned throughput can significantly lower hourly rates.
Beyond model and inference fees, you may incur costs for data transfers across regions, storing custom models monthly, or running evaluation tools for monitoring and testing. These charges can add up and should be factored into your overall deployment budget.
Amazon Bedrock’s flexible pricing accommodates a wide range of AI use cases, but it is important to match your architecture and usage with the right pricing model. With smart planning, including balancing on-demand versus provisioned throughput, using caching, and choosing the right models, teams can build and scale generative AI applications while keeping costs under control.
Discover how Amazon Bedrock simplifies AI development with serverless access to top foundation models, customizable options, and cost-efficient...
Comparing and contrasting between Bedrock and OpenAI and why Bedrock might be better.
Learn how to choose the right GenAI model for your business with insights on AWS Bedrock and key industry players. Discover our expert tips and...