Artificial Intelligence
Three Lessons Learned from Working in IoT
Prior to coming to Metal Toad, I worked as a .NET engineer at an Internet of Things (IoT) startup.
Extend your AWS Bedrock models with Knowledge Bases to enhance retrieval-augmented generation, leveraging large context windows and efficient data management strategies.

Amazon Bedrock Knowledge Bases is managed RAG: it ingests your documents, builds embeddings in a vector store, and grounds LLM responses with citations, filters, and secure access controls.
An AWS Knowledge Base is to Amazon Bedrock as the Retrieval component is to LangChain🦜🔗. Both offer tools to perform RAG, but Knowledge Bases pair nicely with your Bedrock models, and offer a managed RAG solution that you can quickly standup in front of your foundation models. If you're not already familiar with what I'm talking about, I'll catch you up. Large language models are rad. When used correctly, the information they string together can be profoundly useful, and when given enough "context" alongside clear instruction, we've found these models are capable of integrating that "context" to a similar effect as if it was a traditional ML model trained on the same data.
Learn more about AWS Bedrock Pricing
Models all have a limited context windows. These windows define the size limits of both input and output measured in tokens as a single value. Essentially this is to say it becomes impossible to include the entire contents of data lake if you need this as context for your prompts.
It is worth calling out that as of late we've seen models boasting 100K+ token windows like Anthropic's Claude, and even Google boasting a version of Gemini with a million+ limit. In Bedrock at the time of writing this, Claude V3 Sonnet and Haiku are the largest options with 200k limits.
These large windows enable much more complex prompts without the need for augmenting. Documents that previously may have needed to be chunked, summarized, or otherwise linguistically compressed, may not need to suffer from these lossy tactics with the large enough windows (obviously at a cost in tokens...).
Retrieval Augmented Generation or RAG, is a technique that allows you to create more contextually rich responses from Large Language Models (LLMs). By drawing information from a data store, models can provide more accurate and informative responses to queries/prompts. The AWS Bedrock Knowledge Base approach speeds up development time by providing a ready-to-use solution with consoles, APIs, and tools to manage all the parts. Things like your document loaders, source and vector store, embeddings model, chunking rules, and retriever are all considered and configurable from our favorite 🐬boto3 library (if you're in Python).
Remember however that LangChain is powerful and actively maintained/growing. It does everything that a Knowledge Bases offers, but is agnostic of clouds and models. So don't write it off. If find yourself only needing "part of" or a custom solution you may find it super useful.
LangChain Retrieval: https://python.langchain.com/v0.1/docs/modules/data_connection/
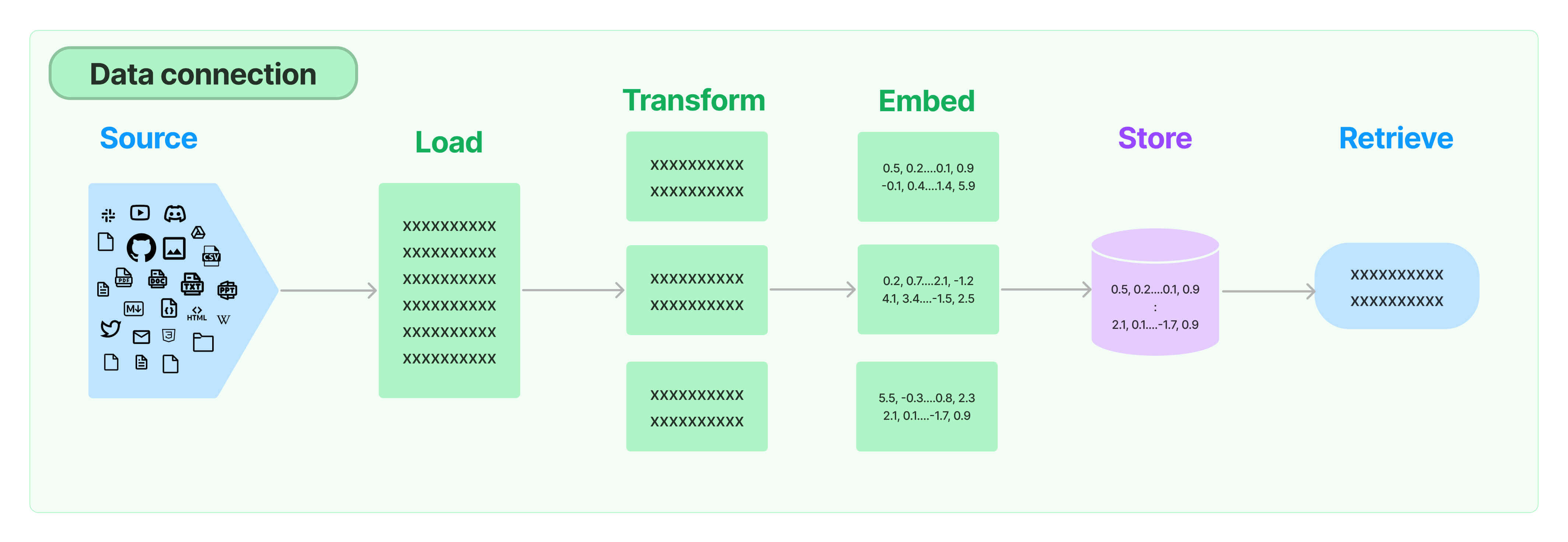
I'm not going to make this a whole tutorial on the setup, AWS has done a great job providing notebooks and documentation on this. Not to mention the Bedrock console provide a great introduction to what these tools do.
This graphic from the AWS Bedrocks Workshops page roughly illustrates the Knowledge Base flow (and definitely note how closely it resembles what we see from LangChain.)
The basic idea that you'll get into when working through the AWS Knowledge Base material is as follows:
1. You setup an S3 Bucket that will serve as your source storage.
2. From this, the contents will be "chunked" or essentially broken down into smaller parts, as intelligently as possible based on a strategy you set.
3. You pick or use the suggested embeddings model, which is just another LLM trained or tuned on the specific task on embeddings.
4. And lastly the vector store is by default OpenSearch, and is very easily managed via your Knowledge Base (console or API).
Okay, but what I really wanted to include was 2 tips for anyone starting out, as the information above is pretty easy to come by.
Consider your embeddings retention policy.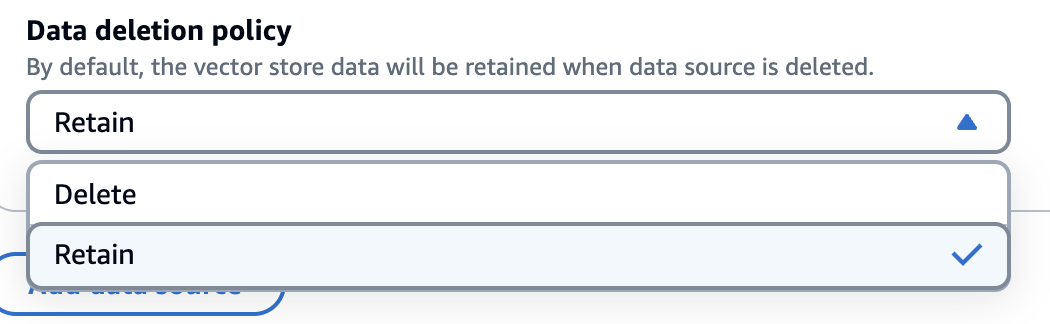
While a simple configuration, its worth thinking about, and might make you really consider how you want to use your Knowledge Base. A Retain policy will persist your vector data regardless of if the source in still available in the S3 bucket. This is great if you want to maintain an ever growing vector store without a massive S3 bucket.
But consider the Delete policy. This will remove the related vector data if the source is deleted from S3. This makes it very easy to control your embeddings, as their existence will just be based on whats in an S3 bucket.
And that takes me to my second tip. When you start using a Knowledge Bases you may quickly find the need to filter or limit what your retriever is allowed to return from. Meaning you may have a large pool of documents, but perhaps you know for a given prompt that you're only concerned with one type of document.
This is where metaDataAttributes and filtering upon retrieval comes in handy.
To include metadata for a file in your data source, create a JSON file consisting of a metadataAttributes field that maps to an object with a key-value pair for each metadata attribute. Then simply upload it to the same folder and bucket as the source document file.
{
"metadataAttributes": {
"${attribute1}": "${value1}",
"${attribute2}": "${value2}",
...
}
}
Append .metadata.json after the file extension (for example, if you have a file named Something.txt, the metadata file must be named Something.txt.metadata.json
Now when performing a retrieval, we can use these attributes to filter what sources the parts are allowed to come from. KnowledgeBaseRetrievalConfiguration
Heres are the tables of operators that can be used to filter.
| Field | Maps to | Filtered results |
|---|---|---|
andAll |
List of up to 5 filter types | Results fulfill all of the filtering expressions in the group |
orAll |
List of up to 5 filter types | Results fulfill at least one of the filtering expressions in the group |
| Field | Supported value data types | Filtered results |
|---|---|---|
equals |
string, number, boolean | Attribute matches the value you provide |
notEquals |
string, number, boolean | Attribute doesn't match the value you provide |
greaterThan |
number | Attribute is greater than the value you provide |
greaterThanOrEquals |
number | Attribute is greater than or equal to the value you provide |
lessThan |
number | Attribute is less than the value you provide |
lessThanOrEquals |
number | Attribute is less than or equal to the value you provide |
in |
list of strings | Attribute is in the list you provide |
notIn |
list of strings | Attribute isn't in the list you provide |
startsWith |
string | Attribute starts with the string you provide (only supported for Amazon OpenSearch Serverless vector stores) |
AWS has more examples in the links above, but heres 2 to give you an idea and get you started.
One filtering operator.
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
}
}
}
}
One logical operator.
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
]
}
}
}
The decision between AWS Bedrock Knowledge Bases and a custom LangChain pipeline often comes down to control versus convenience. Bedrock Knowledge Bases shine when you need a production-ready RAG solution quickly with minimal operational overhead. The managed service handles infrastructure scaling, security patches, and integration with other AWS services out of the box.
Choose Bedrock Knowledge Bases when your team prioritizes speed to market, has limited ML operations experience, or when you're already heavily invested in the AWS ecosystem. The built-in monitoring, automatic backups, and enterprise security features make it ideal for regulated industries or large organizations with strict compliance requirements.
However, LangChain pipelines offer superior flexibility for complex use cases. If you need custom document loaders, specialized chunking strategies, or integration with non-AWS vector stores, LangChain is your friend. Teams with strong Python expertise often prefer LangChain for its extensive customization options and active community support.
Consider a hybrid approach for large organizations: use Bedrock Knowledge Bases for standard document retrieval and LangChain for specialized pipelines that require custom logic. This gives you the best of both worlds while maintaining consistency across different use cases.
The cost factor is nuanced. While Bedrock Knowledge Bases appear more expensive upfront due to managed service premiums, factor in the engineering time saved on infrastructure management, monitoring setup, and maintenance. For many organizations, the total cost of ownership favors the managed solution.
Not all data belongs in a vector store. The choice between vector search and natural-language-to-SQL depends heavily on your data structure and query patterns. Bedrock Knowledge Bases excel with unstructured content like documents, emails, and reports where semantic similarity drives relevance.
For structured data like databases, spreadsheets, or API responses, consider whether your users ask questions that require semantic understanding or precise data retrieval. Questions like "Show me sales trends for Q3" are better served by SQL queries against structured data, while "What factors contributed to our Q3 performance?" benefit from vector search across related documents.
Many successful implementations use a router pattern that determines query intent and directs requests to the appropriate system. Simple classification logic can route numerical queries to SQL endpoints while sending conceptual questions to Knowledge Bases. This hybrid approach maximizes the strengths of both paradigms.
When dealing with semi-structured data like JSON logs or API documentation, consider your retrieval patterns. If users search for specific error codes or API endpoints, traditional search might suffice. But if they ask about relationships between different systems or troubleshooting approaches, vector search becomes valuable.
The metadata filtering capabilities in Bedrock Knowledge Bases can bridge this gap for certain use cases. By extracting structured elements as metadata attributes, you can combine semantic search with precise filtering, giving users the flexibility to ask both specific and conceptual questions against the same dataset.
Your vector store choice significantly impacts both performance and costs. OpenSearch Serverless is the default and often the right choice for most Knowledge Base implementations. It provides automatic scaling, managed infrastructure, and seamless integration with Bedrock's retrieval APIs.
OpenSearch Serverless works well when you have variable query patterns and want hands-off management. The pay-per-use model makes it cost-effective for development and moderate production workloads. However, costs can escalate quickly with high-volume applications or large document corpora.
OpenSearch Managed clusters offer more predictable pricing and better performance for high-throughput applications. If you're running thousands of queries per hour or managing millions of vectors, the fixed-cost model often proves more economical. You also gain access to advanced OpenSearch features and can optimize cluster configuration for your specific use case.
The newer S3 Vectors option represents an interesting middle ground. It provides much lower storage costs while maintaining reasonable query performance for many applications. This approach works particularly well for applications with infrequent queries or when cost optimization is paramount. However, expect higher latency compared to OpenSearch-based solutions.
Consider your query patterns, budget constraints, and operational preferences when choosing. Start with OpenSearch Serverless for proof-of-concepts, then evaluate costs and performance requirements as you scale. Many organizations run multiple vector stores for different use cases rather than forcing everything into a single solution.
Don't forget about geographic considerations. If your users are distributed globally, evaluate whether your chosen vector store can provide acceptable latency across regions. OpenSearch Managed clusters can be deployed in multiple regions, while Serverless and S3 Vectors have more limited geographic options.
The embeddings model choice fundamentally shapes your Knowledge Base performance and costs. Amazon Titan Embeddings G1 offers strong general-purpose performance with 1,536 dimensions and excellent integration with other AWS services. It handles most English-language documents well and provides consistent results across different domains.
Cohere embeddings excel in multilingual scenarios and offer superior performance for certain technical domains. The higher-dimensional options (up to 4,096 dimensions) can capture more nuanced semantic relationships but come with increased storage and computational costs. Cohere's multilingual capabilities make it the preferred choice for global organizations with diverse language requirements.
The dimension count directly impacts both accuracy and cost. Higher dimensions typically provide better semantic understanding but require more storage space and computational resources. For many applications, 1,536 dimensions provide the sweet spot between performance and efficiency. Only increase dimensions when you have specific evidence that your use case benefits from the additional complexity.
The binary versus float32 representation choice represents a crucial performance trade-off. Binary embeddings offer dramatic space savings (up to 32x reduction) and faster retrieval speeds, making them attractive for large-scale implementations. However, they sacrifice some semantic precision, which may impact retrieval quality for nuanced queries.
Float32 representations maintain full semantic fidelity but consume significantly more storage and processing resources. For most production applications, float32 remains the safer choice unless you have specific performance or cost constraints that justify the accuracy trade-off.
Consider your specific use case when making this decision. Technical documentation with precise terminology often benefits from float32 precision, while general corporate communications might work well with binary representations. Run comparative evaluations with your actual data and queries to determine the optimal configuration.
Monitor your retrieval quality metrics closely when experimenting with different embeddings configurations. A slight decrease in storage costs isn't worth significant degradation in user experience. Many organizations implement A/B testing frameworks to continuously optimize their embeddings choices as their data and usage patterns evolve.
Prior to coming to Metal Toad, I worked as a .NET engineer at an Internet of Things (IoT) startup.
I’ve been asked this by several employers recently: “What would you do here if you knew you would not fail?” Not fail?? Not possible…
Discover the basics of machine learning through a practical analogy, covering data gathering, cleaning, hypothesis formation, training, and...