Let's visualize and talk about the "full stack" of web development. From a developer's standpoint, we're probably talking about the layers of code involved in delivering a website to an end user. But let's back up further for a moment and just talk about a stack of things. Given all the different device, language, and application options out there, many stacks of things in this case! There's the stacks involved for phone application development, stacks for websites, stacks for console gaming, and more! To avoid head explosions to the extent possible possible, I'm going to focus on Metal Toad's most common stack.
I'm hungry, so I'm making my stack a bit bigger than just code layers. What I'll attempt to illustrate and explain is the most important layers involved between a web developer and a website visitor, both on their computers. I'll touch on people, software, hardware, languages, concepts, and more in order to provide a fairly holistic view. Much of this stuff (at least on the surface level) isn't as complex as the terminology and acronyms may make it sound. Realize that there are hundreds of intermingled components that this doesn't touch on; if you want the overview, read start to finish, or if you want to get more in-depth, start clicking the links to Wikipedia and beyond. Feel free to call me on any technicalities or suggest changes/additions in the comments!
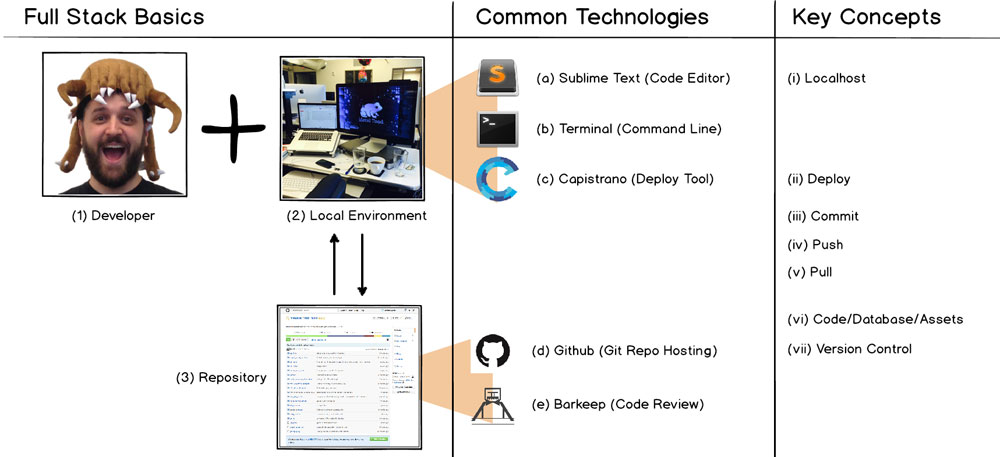
1 - Developer
A developer gets to sit down (or stand up) in front of their desk and build a website. Pretty straightforward here, but note that while some level of knowledge of the full stack is necessary for development, true full stack developers that can write and deliver code from top to bottom at a senior level are rare. Many have a focus in one of three areas (which we'll touch on further below): frontend development, backend development, or devops. A developer will spend much of their time learning, writing code, configuring applications, testing their work, and deploying what they've written.
2 - Local Environment
A local evironment (AKA (i) "localhost" in networking, AKA "local machine") is just a developer's device (laptops in Metal Toad's case). We configure them to develop, test, and deploy websites (AKA "development environment"). These machines are set up with all of the applications installed that make up part of the website's stack so that a developer can write code, deploy it on their own machine, and pull it up in their browser to test and review before committing their work to a repository. Some technologies involved are:
- (a) A code editor is a tool that supports the creation of source code. Since source code is plain text, it can be as simple as a basic text editing program, but many modern editors include tools like syntax highlighting, autocomplete, and formatting to significantly speed development. A current favorite for many of Metal Toad's developers is Sublime Text.
- (b) A command line interface (CLI) in conjunction with a command line interpreter (AKA "shell") is used to run system-level commands via text inputs, as opposed to a graphical user interface (GUI) like OS X and Windows. On Mac computers with OS X (Metal Toad's primary development devices), the bundled application to interact with the operating system via command line interface is Terminal. It's actually an emulator (AKA "imitator") of a command line interface within the OS X GUI. That's not confusing at all. Anyway, OS X is a Unix-based operating system, which means that developers are interacting with the operating system in Terminal using the most common Unix shell, Bash, with Unix commands. But wait, there are shells for more than just operating systems. Programming languages also have shells...
- (c) We use a tool called Capistrano to automate and manage (ii) deployments from local machines to other remote machines. Capistrano is Ruby language-based, so developers interact with it via a Ruby shell in Terminal. If you've heard a developer discuss "cap prod deploy" they're talking about invoking deployment to a production server via the command line.
3 - Repository
A repository is simply a storage location. When the term is used in relation to websites, it generally refers to the organization and storage location for the website's source code files. For most dynamic websites, there are three main components involved: (vi) Code, Database, and Assets.
- Code - Source code is all of the programming language and markup language-based documents and configuration files used to render a website.
- Database - The database is used to store content, settings, user information, and other dynamic elements that interact with/are requested by the source code.
- Assets - In addition to the source code files, websites are comprised of media elements including images and self-hosted videos, as well as PDFs and other types of resources.
A complex website is comprised of hundreds if not thousands of source code files. Managing them all can be confusion and tedious on a one person project; add in multiple developers working on the same code base and a code management system is crucial. This is where (vii) version control comes in. Just like you may be used to creating and managing multiple copies of a draft design PSD or working in Google Drive with multiple collaborators and revisions, version control allows for creation of a revision history and multiple-user collaboration on a shared repository. For version control and repository management, we use (d) Github, which is based on Git. Github is a web-based Git repository hosting service that provides a GUI interface for repository management and source control in addition to command line use.
When it comes to version control and Git specifically, there are a number of terms that you've likely heard mentioned that warrant basic definition:
- Checkout - When a developer starts work on a project with an existing repository, they use the git checkout command and choose which branch (defined below, and generally the "master" branch, or primary branch for the project) they'd like to "check out" and download to create a local copy of the repository.
- (iii) Commit - Much like you would save changes as you go with restore points or copies to revert back to, using the git commit command allows a developer to take a snapshot of their repository and any changes since their last commit as you work. It also requires a comment with the commit explaining the nature of the changes, which will help others debug and determine what changes were made. Developers are encouraged to commit regularly with useful comments for context!
- (iv) Push - Once a developer has gotten to a good stopping point or a point where their local copy of the repository has updates ready to be shared, the git push command allows them to "push" their commits to Github, where other developers can then see the changes.
- (v) Pull - As developers work, they'll want to periodically update their local repository with the changes made by other developers on the project. To do this, they use git pull, which "pulls" the changes down to update their local repository.
- Branch - Branching using git branch allows a developer to work on a version of the repository that is separate from the master. There are several reasons that a developer may want to do this, but often it's for work that requires parralel development on the same repository that shouldn't be rolled out at the same time. A perfect example of this is a new featureset that may take several months to develop for an existing live site. Developers could create a branch for these new features, while maintaining the master branch to be ready for deployment at any time if bugs come up that need quick resolution on the live site.
- Merge - After a developer has completed work in a branch and wants to combine their work with the master branch, they use git merge to merge the branch back into the master. At this point, there's the chance that one or more files have had the same lines of code changed in both master and the branch, and the lines of code don't match. These is called an edit collision, the most common type of merge conflict. Git provides a useful toolset to help developers resolve merge conflicts by determining which code should take precedence.
- Fork - To fork is essentially the same as to branch, the main difference being that when a developer forks a code base, they do so with the intention of not merging the code in the future, and instead often moves forward with the intent of creating a separate piece of software.
With developers regularly committing and pushing changes in a repository, one more important piece of the puzzle is developers giving each other feedback on their work. This is where (e) code review comes into play. For code review we use Barkeep, a system that integrates with Git to allow for seamless peer review and feedback of code while in development.
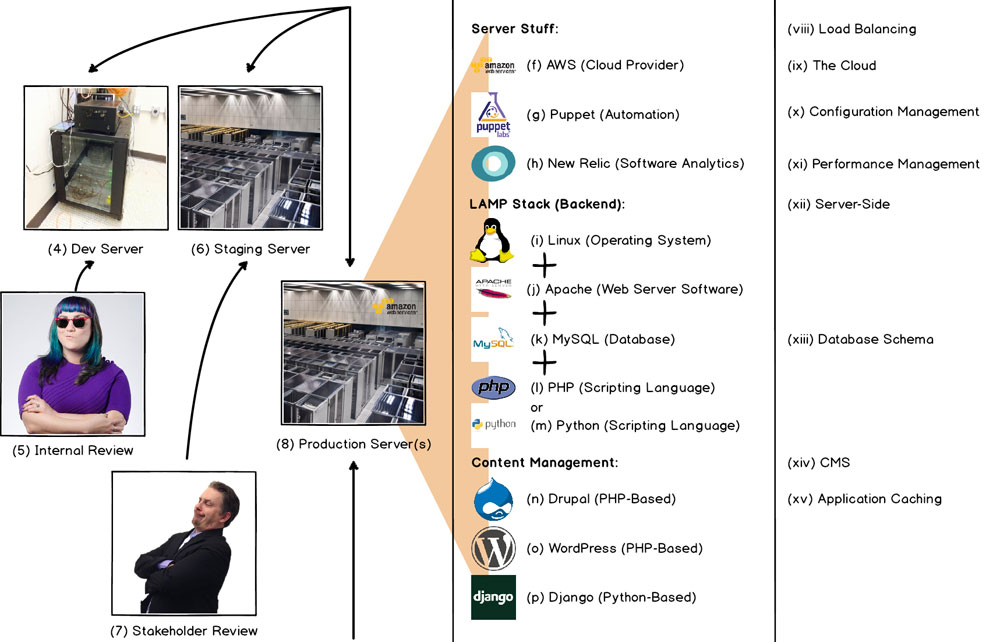
4 - Dev Server
The development server is a web server that handles the next stage of the deployment process on the way to the production environment. As developers are working on a project in Github, the site starts to come together to the point that it's ready to be hosted for internal review, and here's where the dev server comes into play. The dev server has much of the same application stack/development environment that local envinonment does, and the more closely configured the dev server is to the production server software-wise, the better. Ours happens to be a dedicated machine in our server room. Unlike a local environment, the dev server is actually serving websites to a network (which can be controlled to be internal only or accessible via the Internet) so that work in progress can be viewed by means other than looking over a developer's shoulder. When multiple developers are working on a project, the dev server is the best place to deploy their combined code for a first look. Encourage developers to update dev regularly; showing work early and often is healthy!
5 - Internal Review
Here's where more people get involved. The expectation of the website on the dev server is that it displays active work in progress and therefore is at times broken and/or buggy. When a website is early in development, parts may be complete and others haven't even been touched yet. When a website is live on the Internet but also in continued development, the dev server's in-progress development may actually be less functional than the live website due to regression. While the dev server's main purpose is to show work in progress, it also serves as initial QA and testing ground to allow for behavior-driven development. Our QA team can do automated testing with Behat, hands-on exploratory testing, or any of the other multitude of types of software testing that exist.
6 - Staging Server
The staging server is yet another web server in the deployment process prior to the production server. Any number of servers can exist between the local environment and the production server (see chart), but the two we regularly employ are dev and staging. The more closely configured the staging server is to the production server software AND hardware-wise, the better. This allows a higher level of confidence that no issues will show up in production that can't also be reproduced on staging, and initial performance testing/load testing can be completed to ensure software performance assuming the hardware somewhat resembles production. The process of deploying to the staging server is essentially the same as the dev server deployment, just with a different target environment.
7 - Stakeholder Review
Staging is usually the first environment that external project stakeholders review, as the deployments made to staging are less frequent and the work is more polished than dev. Clients and development partners test and accept our work on the staging server prior to our deployment to production. For a new site that is not yet live in a production environment, initial content entry and site configuration often occurs in staging as well so that the site is fully ready to be seen by the world when it goes live on production.
8 - Production Server(s)
At last, we've arrived at the production server! Or servers! Depending on the the number of visitors the website receives and the amount of data that needs to be transmitted, multiple servers with (viii) load balancing may be necessary in order to handle the website traffic. This (and dev/staging servers for that matter) could be either a virtual server (essentially only part a of a physical machine's resources running a virtualized copy of the full stack from operating system to website code) or a dedicated server (a physical server solely used for hosting a single website). It could be an old desktop computer running server software in the office closet or it could be a server in (ix) the cloud. Kudos, by the way, to whoever came up with the buzzwordy "cloud" label applied to what is essentially nothing more than one or more networked data centers. The cloud is much less some ethereal place where data lives, and much more huge infrastructure intended to provide high availability and performance for web hosting. Our go-to these days for cloud services (as it is for many developers) is (f) Amazon Web Services (AWS), which has the most tools for server management and the biggest cloud network available. We often run (g) Puppet on our servers to allow for automation of server-level (x) configuration management, saving our Managed Cloud team huge amounts of time and manual effort. Further, (h) New Relic and similar analytics tools allow us to review and (xi) manage performance of software and hardware on our servers, aiding troubleshooting performance problems. DevOps, or the intersection of development and IT operations, is primarily concerned with this server configuration and software management.
With hardware to host the website out of the way, let's finally turn to the software and languages involved in creating and serving a website. These parts of the technology stack are the same across dev, staging, and production environments. At the core is the open source LAMP stack, which is the primary domain of a backend developer focused on the (xii) server-side in the client-server model:
- (i) Linux is the operating system that runs on our servers. It's a Unix-like operating system, so applications that run on our servers usually also run on our local Mac environments. Beyond the user experience of OS X, that's a big part of the reason we develop on Macs.
- (j) Apache is the web server software running that allows users to connect to the server and make requests using hypertext transfer protocol (HTTP). Yep, that's what that http:// or https:// start to a URL address is all about.
- (k) MySQL is the software used to manage the relational databases of dynamic websites. It is managed via command line, but there are a number of GUI interfaces (phpMyAdmin being a common one) that allow for database administration as well. When it comes to content management systems (covered below), they are programmed to interact directly with the database without human assistance.
- (l) PHP and (m) Python are two of the primary server-side languages we use for development. Note that this is one area where websites that use scripting languages differ from mobile applications which are compiled to be downloaded from an app store and run locally on the mobile device. Instead, these scripting languages are interpreted from one language into something else, in what's known as preprocessing.
That brings us to the (xiv) CMS, or content management system. The ultimate goal of the CMS is to allow website editors and administrators to make configuration changes, content changes, and generally manage their website without needing to know programming languages. The more content changes on a website and the more content-heavy the website, the more a CMS is called for. A CMS relies heavily on a content model that matches the (xiii) database schema. For instance, with an example of a simple blog, there will be multiple posts, and each post needs a unique key (often an ID), a title, an author (who is often a site user), a date, the post body, and the multiple comments related to that blog. Each comment also needs to have a unique key, a commentor name, a date, a subject line, and a comment body. The oversimplified database schema could look something like:
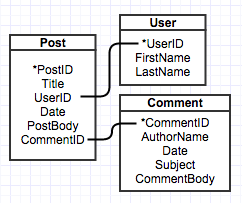
Within the relational database, each of the three types of content has a table. Within each table the fields make up the individual columns, and the rows are populated by the numerous individual pieces of content. Because of all the unique content and different requests for specific content from users causing extra load on the server, most CMS offer (xv) application-level caching to build cached versions of commonly requested pages from site visitors. Wondering why you're not seeing the changes you just made to your website? Try clearing the application caches! Metal Toad works with a number of different content management offerings, most notably (n) Drupal (a PHP-based enterprise-ready CMS), (o) WordPress (a PHP-based CMS used by a huge number of websites), and (p) django (our Python go-to for databased managed projects that require a content framework rather than a full-blown CMS).
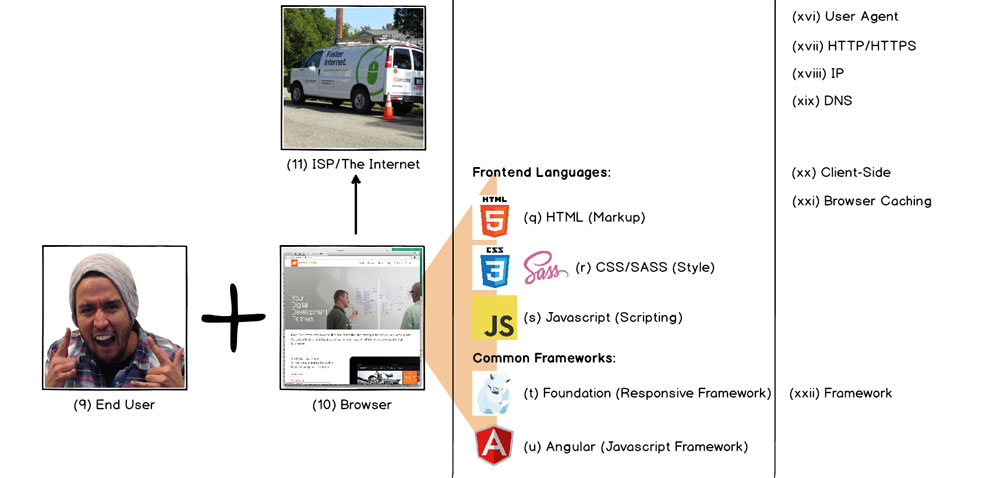
9 - End User
Still with me? Great! Now that we've covered the basics of a developer writing and deploying code all the way to a production server, let's jump all the way to the bottom of the diagram and work our way back up from the end user to discover how they reach the website on the production server. This same process applies to how a user visits the staging server and development server (if publicly accessible) as well. The user is going to need a computer (their own "localhost"), but they don't need any particular software installed other than a web browser!
10 - Browser
Ah, the good old web browser. Luckily the days of Internet Explorer 6 are over and we've moved on to browsers that can handle the plethora of modern languages, frameworks, and applications that make up the many pieces and parts of a website. We generally favor Google Chrome. We're now on the (xx) client-side in the client-server model, or the frontend presentation layer portion of a website. Here's the part where you regularly remind website users (and yourself), "did you clear the cache?" when expected changes to a site aren't showing up. Caching layers appear all over in the web development stack, but your browser will make ample use of (xxi) browser caching in order to speed up your web browsing experience at the expense of potentially failing to deliver the newest content.
Let's talk some technologies and concepts when it comes to the client side:
- (q) HTML makes up the building blocks of every website. Note that many programmers will correct you if you call it a programming language, as it's actually a markup language. HTML is interpreted by the browser using the DOM convention for structure, resulting in the website you see in front of you! HTML can also be used to build entire static web pages without any dynamic code involved.
- (r) CSS comes in really handy at this point for your structured but unstyled website. CSS is a style sheet language that provides the look and formatting for HTML. CSS can be written in-line in an HTML document, but the modern standard is to have the HTML file reference the CSS file and keep all style information separate to make global style updates easier. We use SASS in addition to CSS to bring a bit more power to our frontend. SASS relies on similar principles to scripting languages to take SASS files and preprocess them into normal CSS much the same way preprocessed PHP code spits out HTML.
- (s) Javascript is our other go-to frontend language, bringing dynamic code to the frontend. Why have the server do all the work when your own computer+browser is plenty capable? One of the biggest breakthroughs Javascript has allowed is the ability to alter the contents of a website once it has completed initial loading from the server with asynchronous communication (AJAX). This allows for features you see in modern websites like "load more", form submission, search result autocomplete, and other tasks that might otherwise require a page reload and new information preprocessed on the server.
The HTML/CSS/Javascript cobination is a powerful one, but like much of programming, frameworks can speed up development significantly. I've used the term (xxii) "framework" (or the related "library" with the primary distinction being that frameworks are installed and run on your servers, while libraries are often hosted externally for a website to reference) a few times already, so I should clarify what that's all about. Really all we're talking about is a bundle of code that has been abstracted to a general set of beneficial features for reuse and/or modification. We use quite a few frameworks and libraries in development. Drupal itself, while considered a CMS, is sometimes referred to as a content management framework due to the level of abstraction and multitude of potential use options it provides. jQuery is by far the web's most popular Javascript library, allowing for better separation of Javascript from HTML and better cross-browser compatibility out of the box. There are two key frontend frameworks that we make heavy use of at present:
- (t) Foundation is a HTML/CSS/Javascript framework that is hugely beneficial when developing responsive websites. Given the request from just about every client project to build responsively, Foundation is useful in getting some out-of-the-box responsive benefits even before starting custom responsive work.
- (u) AngularJS is a Google-developed Javascript MVW (as opposed to MVC) application framework that can relieve the backend of a large amount of templating work. We're doing more and more prototyping work in Angular, and an increasingly common scenario is using "headless" Drupal, or using Drupal as a framework for content management, and using Drupal's API to handle all templating and front-end development in Angular.
As mentioned above, unlike backend languages such as PHP (which takes client requests for dynamic content and interprets them into HTML on the server before being served to the client), frontend languages are delivered as written to the browser, and then any frontend scripts are run in the browser. The easiest way to visualize this is to pull up a web page's source code. You see client-side code (HTML, with links to CSS and Javascript files and libraries) but no backend languages, as those files have already run on the server and spit out their resulting code:
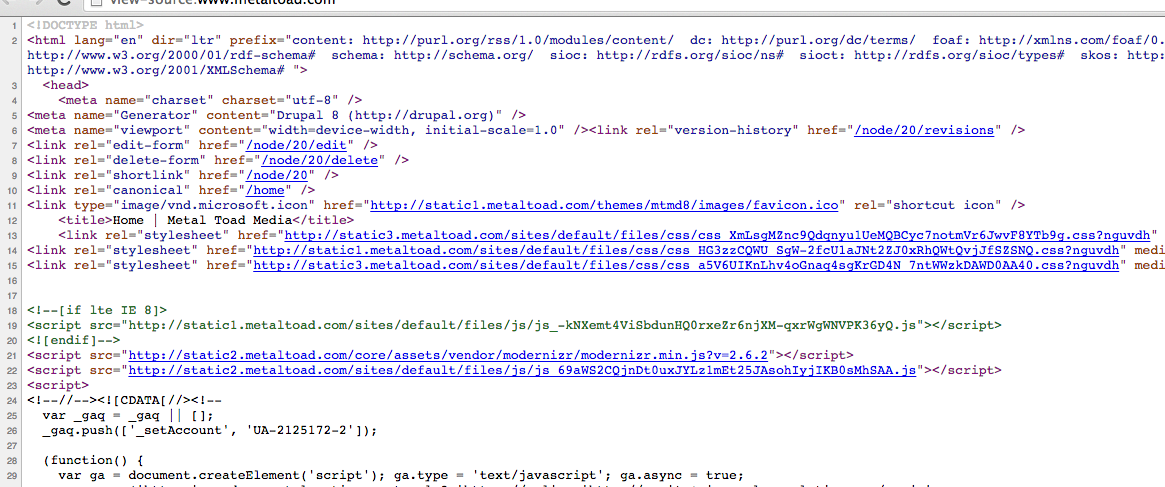
Further, when you pull up Chrome's Developer Tools or a similar browser inspector (the best thing ever to happen to frontend development) and take a look at the files loaded by the browser, you can see HTML, CSS, and Javascript files, but no sign of any backend code:
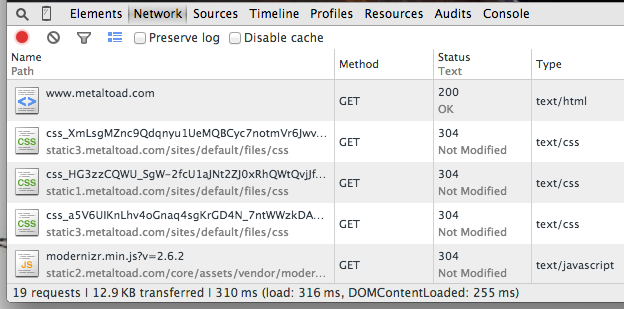
Note that the increasingly widespread acceptance of open source has allowed the frontend to become a much more viable and powerful playground for developers. Server-side backend languages are great for protecting proprietary code because the end user never has access to that code, but frontend languages are all sent to the browser for interpretation, so the source code is all accessible simply by nature of where it's processed.
So far we've covered how the production server and the browser both contribute to creating the websites you browse every day, but there's one big question remaining to be answered: how are your browser and the production server communicating? That brings us to...
11 - ISP/The Internet
Oh right, there's that handy thing called The Internets, the handy series of tubes that has given purpose to and led to the development and maturation of every other part of the stack. Underlying the Internet are a number of important concepts. First off, remember that the Internet is essentially a huge internconnected web of smaller networks and numerous devices within those networks. Between all parts of all networks, connections exist comprised of either physical cables or over-the-air wireless (radio) connections. ISPs, or Internet Service Providers manage access to the Internet for private households and mega-corporations alike. Here is where battle over net neutrality is occuring, and you can probably see why it's important to the Internet's future that ISPs treat all data coming and going on their networks equally. ISPs are poorly regulated, and my hope is that they eventually fall under the same status as a public utility like sewer/water or electicity.
But back to the tech. ISPs are facilitating huge numbers of outbound requests from (xvi) user agents (browsers being the most common user agent involved when it comes to websites) seeking a destination production server and whatever it is that server has to return. The web browser's URL address holds the key to what it is being sought out and where:

- The (xvii) HTTP/HTTPS protocols specify the type of request being sent to the intended server, where Apache will interpret the request and provide the proper response.
- The hostname (the server's name, essentially) is made up of both the www and the domain name. Hostnames actually represent an (xviii) IP address and are intended as a human-readable alternative to typing in strings of numbers to reach target hosts. The www subdomain (or any other of subdomains that can be created) allows the host server to identify if a specific server or resource on a server is being requested. For instance, www exists as a hostname for metaltoad.com, but dgsdaghrwehr.metaltoad.com does not.
- The domain name consists of a top-level domain (.com in this case) and the unique name (metaltoad) that we registered for use as our human-readable represenation of our production server's IP address.
- The directory portion of the URL tells the server where within the overall server directory the requested file lives. The initial / indicates the server's root directory, so in this case the URL is requesting a file within the "files" directory, which lives within the "default" directory, which lives within the "sites" directory in the root directory. Confused? Directories are synonymous with the folders you're likely very used to using in your operating system's GUI file system browser. So just think folders inside folders.
- The file name is pretty straightforward. In this case, the requested file is a .jpg image. You'll see many URLs without a filename, and in these cases, there are rewrite rules within Apache that take a URL and determine which file to serve.
All of this relies on the overarching (xix) Domain Name System (DNS) comprised physically of a distributed network of domain name servers which handle translation of domain names and IP addresses. DNS specifies authoratative name servers for each domain name, and those name servers handle a zone file for each individual domain name. Within the zone file, a variety of DNS record types can exist. The two most pertinent for website purposes are A records (specifies the IP address for a hostname) and CNAME records (creates aliases from one name to another). Using our site's example, www.metaltoad.com has the following records in its zone file:

Metaltoad.com has an A record that specifies the host/server with an IP address of 54.186.179.92. There's also a CNAME that exists that ensures website visitors arrive at our website whether they attempt to visit http://www.metaltoad.com or the shorter http://metaltoad.com.
Note that ISPs also tend to employ some caching, and domain name servers assign individual DNS records a TTL (time to live) which (if you forget to lower the value prior to making record changes) results in the classic case of:
Developer: "We've deployed the site to production and pointed your domain name at the server. Congrats on your live site!"
Client: "But I pulled up the URL address and I don't see it yet."
Developer: "Oh right, well give it 24 hours for the site to propagate across the Internet."
Client: "Bummer."
That's a Wrap (For Now)
What started out as one blog post morphed into a series (as they tend to do) with a lot of information to absorb. If you picked up the overaching picture of how all these pieces and parts tie together, great. If you're still confused or have areas you'd like clarified or further described, let me know. I'm happy to make updates, so please leave a comment!
Additional Resources:
- Full Stack Python is a slightly more technical and much more in-depth look at the full stack with a specific emphasis on Python.
- The Google is a wonderful place where any sort of answer can be had as long as you know the question to ask.
- Stack Overflow is a big repository of development questions and answers. It's a lot of by-dev, for-dev reading, but armed with the Google you should be able to work your way through any sort of techincal topic to your heart's content!
- Atlassian's Git tutorial provides useful basics on Git and version control
- Github for Beginners provides some useful basics on Github and basic commands.
- MIT IT has a useful resource for learning more about the domain name system.
- DNSimple also has useful articles on DNS and record types.

{kind=link}
{kind=link}