Drupal
Date-boosting Solr / Drupal search results
By replacing Drupal's core search with Solr, it's possible to gain very fine control of the results. Not only is Solr very flexble, but the...
Using Apache Solr with Drupal is fairly simple thanks to the apachesolr module, but recently we were tasked with making Solr a vital component.
Using Apache Solr with Drupal is fairly simple thanks to the apachesolr module, but recently we were tasked with making Solr a vital component of a custom Django project. The Drupal module comes with a Solr schema.xml that is already set up specifically to play nice with Drupal, but we had to craft our own. Setting up Solr, filling it with data, and getting it back out again is relatively easy. However, much like taking a north-Philly street brawler and turning him into Rocky, it takes a bit of work to do it well.
Possibly the single most important factor in successfully creating a custom Solr schema is how well you know the data. This is where a slight bit of artisanship comes into play. To be as efficient as possible the schema has to reflect not just the data types, but where the data needs to go and how it is going to be used on a field by field basis.
Anytime that I move data from one point to another, I always take some time to plot out all of the data that I start out with, and were exactly it needs to go. In this case, not just where it needs to go in Solr, but where and how it will be used by viewers of the final site. Only after I have answered those questions do I start thinking about the mapping and how to get it there. For simple one-to-one migrations of data, that process might get you most of the way there, but with Solr you need to be mindful of many other factors.
The Solr schema.xml (typically found in the solr/conf/ directory) is where you tell Solr what types of fields you plan to support, how those types will be analyzed, and what fields you are going to make available for import and queries. Solr will then base its Lucene underbelly on what you define. After installation you will have a generic example schema.xml that I highly recommend you read through and even use as a foundation of your own schema. It can be tempting to glaze over large block comments in an example file, but you will find great examples, explanations, and even some solid performance and tuning tips all through the file. It is definitely worth the time to read it over before you set up camp and make it your own.
The big picture of the file really breaks down to three major areas. First you define your field types to dictate which Solr java class the field type utilizes and how fields of this type will be analyzed. This is where most of the "magic" is outlined in your schema.
Then you define your actual fields. A field has a name attribute which is what you will use when importing and querying your data, and it points back to a designated field type. This is where you tell Solr what data is indexed, and what data is stored.
Optionally you may choose to have some copy fields which can be used to 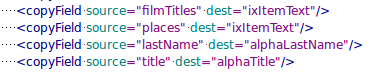 intercept incoming data going to one field and fork a clone of it off to another field that is free to be a different field type.
intercept incoming data going to one field and fork a clone of it off to another field that is free to be a different field type.
A concept in Solr that you do not want to miss out on is that not everything has to be indexed and not everything has to be stored. Solr takes a dual path with data, keeping what is indexed completely separate from what is stored. When you think about the complex operations that Solr does on your data to dissect, convert, and if you say so - even turn it backwards in order to make it indexable, it makes sense that you would not be able to turn around and reuse that same data to display back to the viewer. So now you have two fundamental questions to ask yourself on each field:
The answers to these questions are directly reflected in the indexed and stored attributes to your field elements. These days even terabytes are relatively cheap, but performance is still priceless. If Solr doesn't need it, don't make it wade through it to get what it does need.
Much of the power of Solr comes from the field types that you define and what combination of char filters, tokenizers, and token filters you use against your data. When you set up a field type you can define one shared analyzer or one for the index, and a completely different one for query results.
Within your analyzer(s) you can start out with char filters. A char filter will modify your data in some way before it is actually analyzed. A good example would be the PatternReplaceCharFilterFactory which can apply a regular expression find/replace on your data before Solr even starts to break it apart.
Each analyzer can have one tokenizer. Which one you use will depend heavily on the data you intend to pass through it. Think of this as the fundamental way that you want the analysis of the data to be approached. From there you can also apply token filters to further manipulate your data. Examples would be referencing a stop words list, applying a list of synonyms, or forcing all characters to lowercase.
A great example of this would be if you were going to index and store a document that had plenty of content, but also thick with html markup. When you index that data you want to make sure the mark up is not getting indexed, otherwise things like class names might give you false positives down the road. However when you go to serve up the content to the viewer you are going to want that html intact. Solr can handle this by allowing you to define a field type where the index analyzer uses the HTMLStripCharFilterFactory char filter to purge out all html entities prior to tokenization, but the query analyzer would not use the char filter and instead present the originally stored content in search results.
The most common usage of dynamic fields is to allow your scripts to pass in data with a suffix like "_s" (example: address_s) and then Solr will process whatever you pass as a string. This comes in handy when you have data structures that may change over time and you want to allow your scripts to handle this gracefully without coder intervention on either the scripts or the schema. The Drupal module makes heavy and clever use of this feature. The two downsides are that typically your dynamic fields are going to be have more generalized tokenizers and filters applied and they are most likely going to index and store everything in order to play friendly with any data you throw at it. Whenever possible I would recommend defining specific fields for any data that is going to carry significant weight in your indexing or queries. This will allow you to get much more granular with how that data is processed.
If you need the same field to be indexed or stored in more than one way, there is no need to modify your scripts to send the same field twice. Just utilize the copy field feature of Solr. Another useful trick is to use copy fields to combine multiple fields into one indexable field. This can greatly simply running queries.
If you have not installed Solr yet, you can find the download and install documentation here: http://lucene.apache.org/solr/downloads.html.
If you are just experimenting you can get by running from the Jetty Java servlet container that comes with the download. But for production and serious development you will want to upgrade to something with a little more muscle like Apache Tomcat to dish out your Solr needs.
 If this is your first time working with Solr I would recommend spending some time just experimenting with the solr/admin/ interface. A lot can be learned from pushing in some of the example xml files and testing out some queries. This is also a great place to test out your latest field type concoctions.
If this is your first time working with Solr I would recommend spending some time just experimenting with the solr/admin/ interface. A lot can be learned from pushing in some of the example xml files and testing out some queries. This is also a great place to test out your latest field type concoctions.
Some great documentation is provided on some of the most common tokenizers and filters in the apache.org wiki. If those do not meet all of your needs you can also find plenty of others out in the wild. For example, we needed a geo hash that could handle multiple values on a field, so we tracked down and used an alternative for the single value one that comes with Solr.
You will find a lot of material and concepts at play and the best way to find your bearings is to just dive in. When in doubt, push some data, query it, refine the schema as needed.
By replacing Drupal's core search with Solr, it's possible to gain very fine control of the results. Not only is Solr very flexble, but the...
Metal Toad has had the privilege to work over the past two years with DC Comics. What makes this partnership even more exciting, is that the main...
Join Michael Brooks as he discusses the Apache Cordova, the importance of open source designers, tech writers, and how join the PhoneGap community.